Recently DITAWriter (AKA Keith Schengili-Roberts) posted a series of interviews (here, here and here) about the uptake of DITA in the Semiconductor industry. For those of you who have never heard of DITA, in short, it is an OASIS XML standard for authoring and publishing modular topic-based content.
One of the interviews was with our very own Colin Maudry, so I thought it would be useful to expand on how NXP is using DITA and give some facts and figures.
As mentioned in the interview, we primarily use DITA as the source format for what we call our “value propositions”. This content is essentially the marketing narrative about our products and consists of a description, features and applications plus a few other optional bits and pieces. This content ends up in a few different outputs including: data sheets, product web pages and mobile apps as shown in the following diagram.
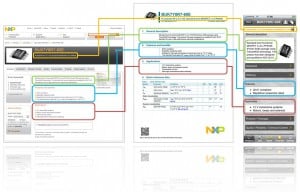
Each of the circled bits of content is a topic, which is a discrete content resource that can be reused across multiple documents (or maps in DITA-speak). This is particularly useful for applications lists, for example, where many products share that same list of ‘standard’ applications. This pays dividends when translating as we do not end up translating the same content time and time again, which results in more consistent translated content and lower costs.
Here are a few of the reasons we have chosen DITA:
- Provides an ‘agnostic’ source format for multiple output formats
- Separates content structure (meaning) from style (look and feel)
- Topic-based approach enables content to be easily reused across documents
- Offers native support for translation/localization
- As it’s XML based, can be integrated to existing XML publication processes
- It’s an open standard so better tool support and a broader user community
Of course, we have not been using DITA since the dawn of time so we had to migrate the content from legacy formats into DITA. Luckily for us all of our legacy source formats were XML, so it was relatively simple to transform this to the DITA target format using XSLT. The migration took place in two main rounds. During the first round we ignored any potential reuse and migrated each document with it’s own set of topics, whereas during the second round we tried to de-duplicate any topics where the content was identical.
Roughly 50% of our new data sheets are still created using proprietary (SGML) EDDs in Adobe FrameMaker. For these we still have to (manually) extract the content into DITA following publication, but this is something we are seeking to automate in the near future with the longer-term goal to move to DITA as the source format for all natural language content. For the other 50% of data sheets the DITA value propositions are used when we generate the data sheet along with other topics generated on-the-fly from our product information database (more on that in another post).
Having all this content in DITA enabled us to easily translate large volumes of content to Chinese and Japanese (see figures below). We have set up a partially automated workflow to deal with the translation requests, which natively supports DITA and required minimal setup to set a bridge between our content and our translation providers. Without using DITA and related technologies such as XLIFF, such large-scale translation simply would not have been feasible or cost-effective.
Finally here are some stats reflecting the status today:
- Number of DITA maps: 10,000+
- English (source): 6,281
- Chinese: 536
- Japanese: 2,991
- Other: 392
- Number of DITA topics: 40,000+
- On average a map is reused for 2.27 products
- Maximum number of times a map is reused is for 223 products!
- As of December 2012, our source DITA content contained 1,018,093 words including 489,705 repetitions




